FAUN: Federated Adversarial Unlearning for Poisoning Recovery
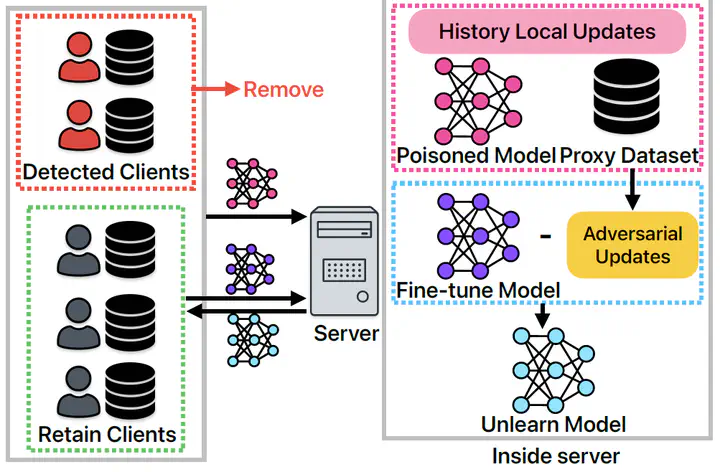 Image credit: Unsplash
Image credit: UnsplashAbstract
Federated learning (FL) is vulnerable to poisoning attacks, where malicious clients upload manipulated updates to degrade the performance of the global model. Although detection methods can identify and remove malicious clients, the model remains affected. Retraining from scratch is effective but costly, and existing unlearning methods remain unsatisfactory in both effectiveness and efficiency. We propose Federated Adversarial Unlearning (FAUN), a lightweight framework that retains only a short window of malicious clients’ updates and employs adversarial optimization on a proxy dataset to derive updates that eliminate malicious directions. Applying these updates for a few unlearning rounds, followed by benign fine-tuning, enables fast removal of malicious effects and stable recovery. Experiments on three canonical datasets show that FAUN achieves recovery comparable to retraining while requiring far fewer rounds and reduces attack success rates to near zero, confirming FAUN successfully eliminates the contributions of unlearned clients.
Add the publication’s full text or supplementary notes here. You can use rich formatting such as including code, math, and images.